ElasticSearch常见问题
1.什么是Elasticsearch?
Elasticsearch是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,是一个基于Lucene构建的开源、分布式、Restful接口,能胜任上百个服务节点的扩展,并支持 PB 级别的数据全文搜索引擎,是一个分布式文档面向文档的NoSQL数据库。
2.什么是全文检索和Lucene?
全文检索:全文检索使用倒排索引,是指通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
lucene:里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。
3.什么是倒排索引?
假设数据库中100w数据,需要扫描100w次来确认是否包含关键词是否匹配所有字符,并且不能将搜索词拆解来检索,倒排索引会拆分假设1000w个词语,在倒排索引中就会有1000w行,并记录每个词语在文档中出现的位置。这个过程叫全文检索。
4.Elasticsearch的特点?
1)一个大型分布式集群,分布式的搜索引擎和分析引擎,处理PB级数据
2)作为传统数据库的一个补充,分布式的文档存储引擎
5.Elasticsearch的传说?
许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。
直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。
后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。
第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 Github 上最活跃的项目之一,他拥有超过300名 contributors(目前736名 contributors )。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…
6.elasticsearch的核心概念?
1.cluster(集群)
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是 “elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。2.node(节点)
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况 下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网 络中的哪些服务器对应于Elasticsearch集群中的哪些节点。3.index(索引)
一个索引就是一个拥有几分相似特征的文档的集合(类似于我们在数据库中的库结构),一个索引由一个名字来标识,并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。4.type(类型)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区(类似于数据库中的表结构),其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。5.document(文档)
一个文档是一个可被索引的基础信息单元(类似于表中的一行数据),文档以 Json 格式来表示6.mapping
ES的mapping非常类似于静态语言中的数据类型:声明一个变量为int类型的变量, 以后这个变量都只能存储int类型的数据。同样的, 一个number类型的mapping字段只能存储number类型的数据。同语言的数据类型相比,mapping还有一些其他的含义,mapping不仅告诉ES一个field中是什么类型的值, 它还告诉ES如何索引数据以及数据是否能被搜索到。7.shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。8.replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
7.集群的健康状况?
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
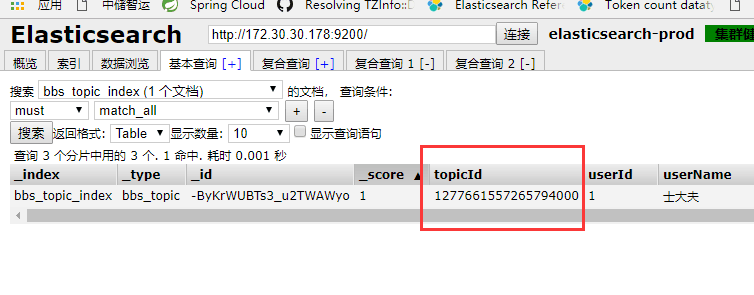
8.查询文档返回结果的含义?
took:耗费了几毫秒
timed_out:是否超时,这里是没有
_shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以)
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据
9.Elasticsearch的垂直扩容与水平扩容
垂直扩容:采购更强大的服务器增加硬件容量,成本非常高昂
水平扩容:采购很多的普通服务器,构成强大的计算和存储能力
10.master节点作用?
默认es会选出一个master节点,主要用于
(1)索引创建或删除
(2)节点增加或删除
11.节点分布式架构?
每个节点都知道任一文档的位置,并转发请求到目标节点。为了扩展负载,更好的做法是轮询所有节点,以单节点免压力过大。
12.文档到分片的位置算法?
ES索引文档到分片遵从公式:shard = hash(routing) % number_of_primary_shards
routing是一个可变值,默认你为文档_id
13.primary shard和replica shard的作用?
每个shard都是一个lucene实例,拥有完整的建立索引和处理请求的能力
replica shard负责容错,以及承担读请求负载
primary shard的默认数量是5,replica默认是1,primary shard的数量一旦创建不可更改
primary shard不会和自己的replica shard放在同一个节点上
14.如何分配shard
每个node有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好
如3台机器:
9个shard(3 primary,6 replica)性能较差,容错好,可同时容纳2台机器宕机,此时应该增加硬件数量来提升吞吐量
6个shard(3 primary,3 replica)性能较好,容错差,可同时容纳1台机器宕机
上面说的是同时,两者都可以容忍2台宕机

15.扩容的极限?
扩容的极限是不会将两个相同副本节点分配到同一个节点
节点数和副本数的关系应该为N>=R+1 (其中N为节点数,R为副本数量)
16.单个Lucene索引中拥有最大数量?
限制是2,147,483,519(= Integer.MAX_VALUE - 128)文件
17.容错机制过程
1)master node宕机,自动master选举
2)replica容错:新master将replica提升为primary shard
3)重启宕机node,master 移动shard到该node,并会进行对原有的shard和目前的primary shard进行同步
18.自动生成的id唯一吗?
自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突
19.Elasticsearch并发冲突问题?
Elasticsearch 是异步和并发的,当文档创建、更新或删除时, 节点之间复制顺序是乱的
es使用_version乐观锁来达到这个目的, 请求时带版本号参数,如果该版本不是当前版本号,请求将会失败
每次对这个document执行修改或者删除操作,都会对这个_version版本号自动加1
20.部分更新(partial update)和全量更新的原理
PUT /index/type/id 创建文档&替换文档,就是一样的语法
一般对应到应用程序中,每次的执行流程基本是这样的:
1、应用程序发起一个get请求,获取到document,展示到前台界面,供用户查看和修改
2、用户在前台界面修改数据,发送到后台
3、后台代码会将用户修改的数据在内存中进行执行,然后封装好修改后的全量数据
4、然后发送PUT请求到es中,进行全量替换
5、es将老的document标记为delete,然后重新创建一个新的documentPOST /index/type/id/_update { "doc" : { "要修改的少数几个field" } }每次就传递几个发生修改的field即可,不需要将全量的document数据发送过去。
实现原理:
其实es内部对partial update的实际操作,更传统的全量替换方式,几乎是一样的
1、内部先获取document
2、将传过来的field更新到document的json中
3、将老的document标记为deleted
4、将修改后的新的document创建出来partial update相较于全量替换的优点:
1、全量替换需要将数据从es中通过java应用程序传输到用户界面,然后用户在前台界面修改后,再通过java应用程序写入到es中去,而partial update的所有查询、修改和写回操作,都发生在es中的一个shard内部,避免了所有网络数据传输的开销(减少了两次网络请求),大大提升了性能
2、全量替换,查询结果放在界面,用户修改就有可能经历10分钟或者更长时间,然后修改完以后再写回去,可能es中的数据早已经被别人修改了,所以并发冲突的情况就会发生的较多。而partial update的查询、修改和写回都发生在es中一个shard内部,一瞬间就完成修改,可能耗时就是毫秒级别的,所以可以大大减少并发冲突的情况。partial update 涉及到的两个知识点:
1、retry_on_conflict = n(如果第一次更新失败,接下来会重新获取新的version版本号,继续尝试更新。这个过程会持续N次)
POST /index/type/id/_update?retry_on_conflict=n
2、version(指定特定的版本号)
POST /index/type/id/_update?version=n
21.document路由到shard原理
路由算法:shard = hash(routing) % number_of_primary_shards
routing值,默认是_id,也可以手动指定,比如:
put /index/type/id?routing=user_id
primary shard数量不可变,否则根据这个公式,之前的数据就找不到了
22.es的增删改原理
增删改只涉及到primary shard,不会由replica shard处理。
(1)客户端选择一个协调节点node发送请求过去,这个node对document进行路由,将请求转发给对应的node(有primary shard),primary shard处理请求,然后将数据同步到replica node
(2)协调节点node如果发现primary node和所有replica node都处理完之后,返回响应结果给客户端
23.es的查询原理
1、客户端发送请求到任意一个协调节点node,这个node对document进行路由,将请求转发对应的node上(此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡)
2、接收请求的node最后的总结果返回document给协调节点node,协调节点node返回document给客户端
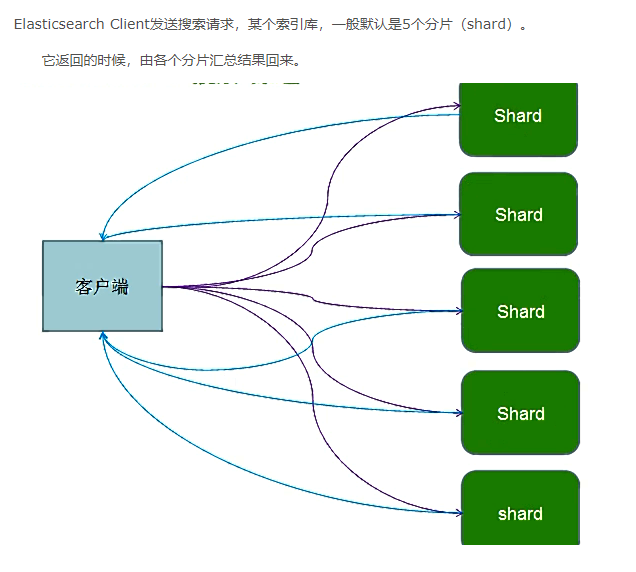
24.timeout机制
搜索时可指定参数timeout 单位ms毫秒 s/秒 m/分钟
GET /_search?timeout=10m
默认是无timeout,但是如果查询很慢就要等待所有结果查出来,指定timeout可在规定时间内
返回每个shard上查到的结果然后就立即返回。
25.分页搜索原理
如果搜索请求一个协调节点,要查询总数30000条中的第500页,查询第5000-5100数据,每个shard上数据是10000条,这时,每个shard返回5100数据,总数15300条给协调节点,然后再对这些数据进行_score排序,取_score最高的10条返回。
因此深度分页性能问题会非常明显的暴露出来官方默认不让返回超过10000条以上数据,index.max_result_window参数限制
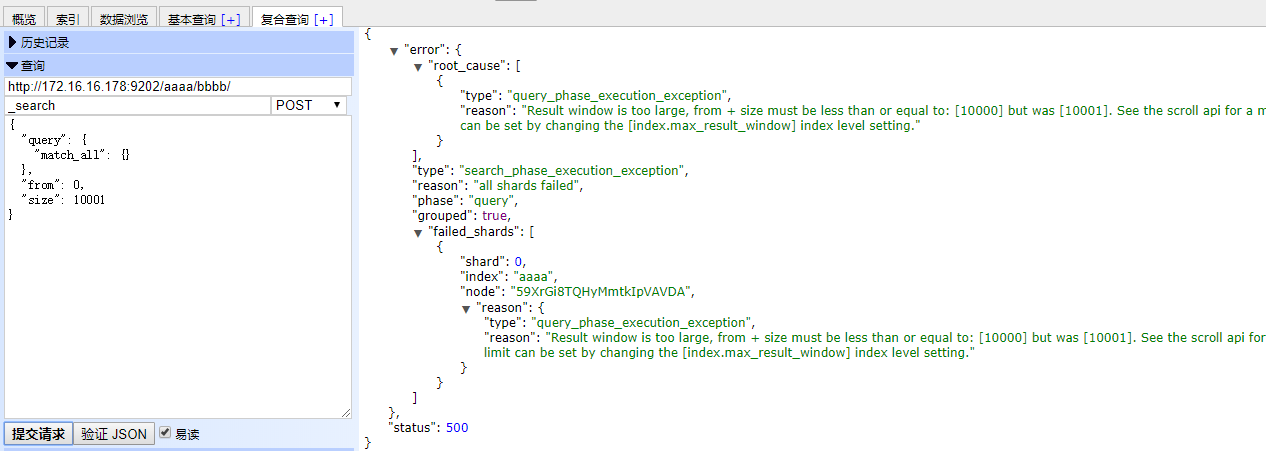
解决:
1.修改index.max_result_window设置值来继续使用from+size做分页查询,这样性能肯定不高。
PUT index/_settings?preserve_existing=true
{
"max_result_window" : "2000000000"
}
2.使用Scroll
如果深度查询性能会很差,一般会采取使用scroll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据
指定一个scoll参数,指定当前scroll的打开时间(只有当前scroll为打开状态,才能获取到值),size返回条数大小
{
"query": {
"match_all": {}
},
"sort": [ "_doc" ],
"size": 3
}
会有一个scoll_id,下一次再发送scoll请求的时候,必须带上这个scoll_id
26.filter与query对比
一般来说,如果搜索需要匹配条件的数据先返回,这些搜索条件要放在query中,反之,不想影响你的排序的条件放到filter
filter,不计算相关度分数,不按照相关度分数排序,同时还内置自动cache最常使用filter的数据
query,计算相关度分数,按照分数进行排序,而且无法cache结果
因此filter性能高于query
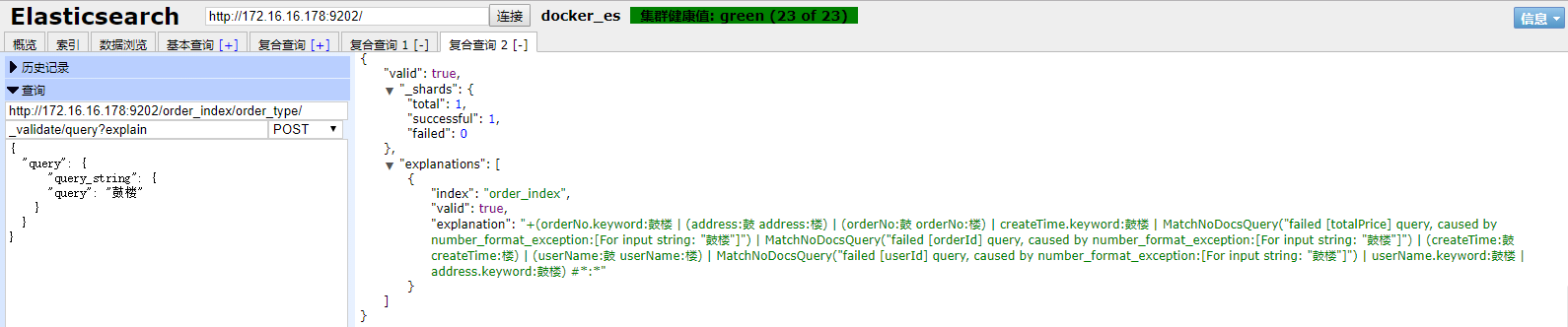
27.如何定位你的查询语法是否合法的详细信息?
POST /order_index/order_type/_validate/query?explain
28.如何解决对字符串进行排序结果不正确的问题?
通常解决方案是,将string field建立两次索引,一个分词,用来搜索;一个不分词,用来排序
注意:字符串排序需要设置Fielddata
PUT /order_index_new/_mapping/order_type
{
"order_type": {
"properties": {
"orderId": {
"type": "long"
},
"userId": {
"type": "long"
},
"userName": {
"type": "text"
},
"totalPrice": {
"type": "float"
},
"address": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"fields": {
"paixu": {
"type": "text",
"fielddata": true
}
},
"fielddata": true
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
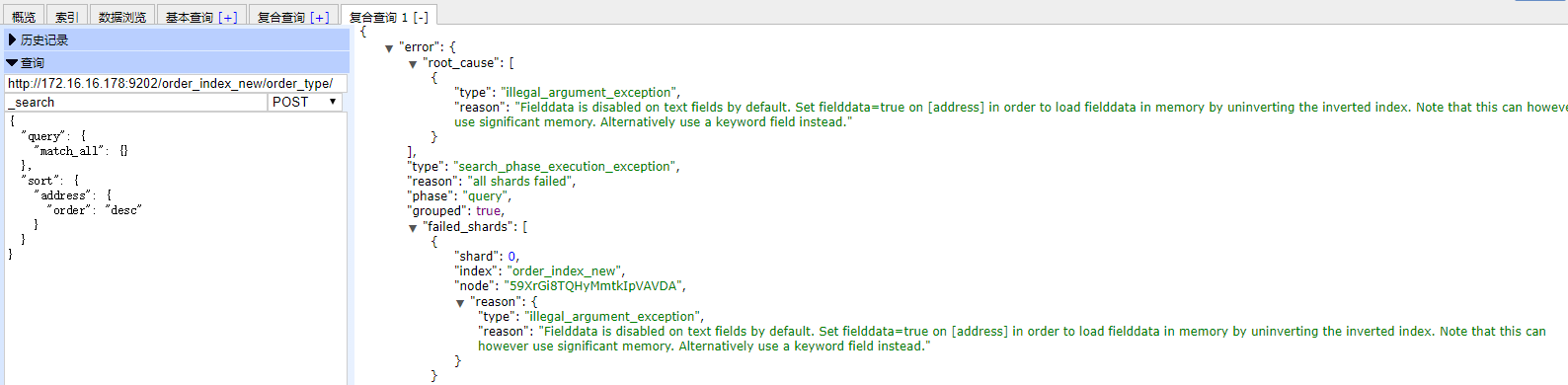
POST order_index_new/order_type/
{
"query": {
"match_all": {}
},
"sort": [
{
"address.paixu": {
"order": "desc"
}
}
]
}
29.正排索引doc values
搜索时,要依靠倒排索引;排序的时候,依靠正排索引,每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values
在建立索引的时候,一方面建立倒排索引,供搜索用;一方面建立正排索引,就是doc values,供排序,聚合,过滤等操作
doc values,如果内存足够,os会自动将其缓存在内存中,性能会很高;如果内存不够,os会将其写入磁盘上
30.集群节点的角色
主(master)节点
node.master设置为True(默认)的时候,它有资格被选作为主节点,控制整个集群。
数据(data)节点
在一个节点上node.data设置为True(默认)的时候。该节点保存数据和执行数据相关的操作,如增删改查,搜索,和聚合
客户端节点
当一个节点的node.master和node.data都设置为false的时候,它既不能保持数据也不能成为主节点,该节点可以作为客户端节点,可以响应用户的情况,把相关操作发送到其他节点
31.关于Head插件的BUG(测试版本6.2.2)
Head插件存在精度问题

32.es中mapping中的enable,store,index参数以及type分词
1.enable 默认是true,只用于mapping中的object字段类型。当设置为false时,其作用是使es不去解析该字段,并且该字段不能被查询和store,只有在_source中才能看到(即查询结果中会显示的_source数据)。设置enabled为false,可以不设置字段类型,默认为object 2.index 默认是true。当设置为false,表明该字段不能被查询,如果查询会报错。但是可以被store。当该文档被查出来时,在_source中也会显示出该字段。 3.store 默认false。store参数的功能和_source有一些相似。我们的数据默认都会在_source中存在。但我们也可以将数据store起来 4.type 如果type是keyword,如果index设为false就是不能搜索了
enable为false不能设置store为true index和store不冲突 enable字段类型为object,设置了enable,不能设置index参数
33.elasticsearch倒排索引结构
搜索的时候,要依靠倒排索引:排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是文档内容。
正排索引是文档 Id 到文档内容、单词的关联关系。也就是说可以通过 Id获取到文档的内容。
倒排索引是单词到文档 Id 的关联关系。也就是说了一通过单词搜索到文档 Id。

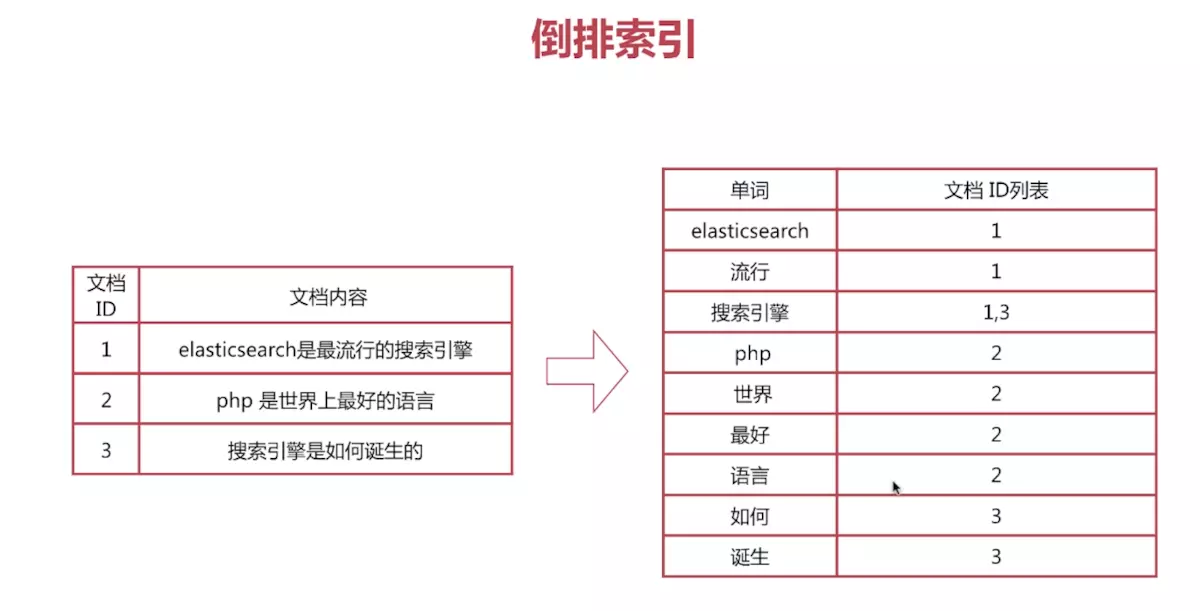
倒排索引的查询流程

倒排索引举例: doc1: hello world you and me doc2: hi, world, how are you
word doc1 doc2 hello world you and me hi how are
hello you --> hello, you
hello --> doc1 you --> doc1,doc2
正排索引举例: doc1: hello world you and me doc2: hi, world, how are you
sort by age doc1: { "name": "jack", "age": 27 } doc2: { "name": "tom", "age": 30 }
document name age doc1 jack 27 doc2 tom 30
正排索引,也会写入磁盘文件中,然后呢,os cache先进行缓存,以提升访问doc value正排索引的性能 如果os cache内存大小不够放得下整个正排索引,就会将doc value的数据写入磁盘文件中
性能问题:给jvm更少内存,64g服务器,给jvm最多16g
es官方是建议,es大量是基于os cache来进行缓存和提升性能的,不建议用jvm内存来进行缓存,那样会导致一定的gc开销和oom问题 给jvm更少的内存,给os cache更大的内存 64g服务器,给jvm最多16g,剩下来的几十个g的内存给os cache os cache可以提升doc value和倒排索引的缓存和查询效率
对于非text字段类型,doc_values默认情况下是打开的。 不需要正排索引的字段,禁用减少磁盘空间的占用,但是该字段不支持排序了
PUT my_index { "mappings": { "my_type": { "properties": { "my_field": { "type": "keyword" "doc_values": false } } } } }
值得注意的是mapping中的字段我们确定以后不会基于这个字段做排序或者聚合,可以把它关掉,但是一定要非常明确你的这个操作,因为如果要重新打开doc_values,需要重建索引,这个在生产环境下还是要谨慎。
34.MySQL和Lucene索引对比分析
https://www.csdn.net/gather_21/MtTaMgysMDMyMi1ibG9n.html https://www.cnblogs.com/luxiaoxun/p/5452502.html